梦倒塌的地方 今已爬满青苔
前言
这个是一个关于链表看代码的时候,发现的一些关于二级指针和运算符的问题。
问题
在看代码的时候,发现了这样一个问题,pTail指针没有分配空间直接使用了,虽然程序没有问题,但是很明显是错误的。通过修改,在其中发现的一些问题。
int createList(LIST **ppList) //一般我们都将指向单链表第一个结点(或表头结点)的指针命名为head,这是习惯约定
{
struct LIST *pNewList;
struct NODE *pNewNode;
if (ppList==NULL)
return PARAM_ERROR;
pNewNode = (struct NODE *)malloc(sizeof(struct NODE)); //申请空间,注意:申请的是一个表结点的空间(28个字节)
if (pNewNode==NULL)
{
return MALLOC_ERROR;
}
memset(pNewNode, 0, sizeof(struct NODE));//void *memset(void *s,int c,size_t n)
pNewNode->next = NULL;
pNewList = (struct LIST *)malloc(sizeof(struct LIST));
if (pNewList==NULL)
{
free(pNewNode);
return MALLOC_ERROR;
}
memset(pNewList, 0, sizeof(struct LIST));
pNewList->Count= 0;
pNewList->pHeadOfData = pNewNode; //表对象的数据指针指向刚才建好的表头结点。
//以下添加了一行代码
pNewList->pTailOfData= pNewNode;
*ppList = pNewList; //给表头指针赋值为表头结点的地址。
//这是套路,先用一个临时变量pNewList去操作数据,然后交付给*ppList
return 0;
}
int createList2(LIST **ppList)
{
struct NODE *pNew;
struct NODE *pTail;
Elemtype Data;
if (ppList==NULL)
return PARAM_ERROR;
createList(ppList);
printf("请输入学生的5位证件号的值和姓名(空格隔开,ID值为0表示输入结束):");
scanf("%ld", &(Data.ID));
scanf("%s", Data.name);
//创建并挂接后续的各个结点
while (Data.ID != END_ID)
{
//创建新的结点并赋值
pNew = (struct NODE *)malloc(sizeof(struct NODE)); //申请空间
if (pNew==NULL)
{
return MALLOC_ERROR;
}
memset(pNew, 0, sizeof(struct NODE));
pNew->data.ID= Data.ID;
memcpy(pNew->data.name, Data.name, strlen(Data.name));
pNew->next = NULL;
//将新结点挂接到原链表中,此步骤很关键!
/* pTail->next = pNew;
pTail = pNew;
*/
//上面是出问题的地方
(*ppList)->pTailOfData->next = pNew;
(*ppList)->pTailOfData= pNew;
printf("请输入学生的5位证件号的值和姓名(空格隔开,ID值为0表示输入结束):");
scanf("%ld", &(Data.ID));
scanf("%s", Data.name);
}
return 0;
}
最开始我在createList2()中的修改如下:
接下来是的问题:
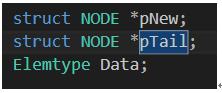
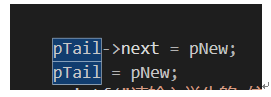
看linklist中的代码ptail就直接声明了就等于了,我都懵了,根本没有分配空间啊。
问题
问题:
ppList->pTailOfData->next = pNew;
ppList->pTailOfData = pNew;
这是我自己写的
我们一步一步来分析:
首先二级指针的概念问题
在creatlist中有这样一段语句*ppList = pNewList;//pnewlist是一个指向列表的指针,记住他是指针调用其内部的语法应该是这样的:pNewList->pHeadOfData = pNewNode;
那么从逻辑上讲语句应该是
*ppList->pTailOfData = pNew;这样才等价于pNewList->pHeadOfData = pNewNode;
我以为这样就没问题了但是提示信息还是一样的
->pTailOfData左边应该是一个类/结构体/联合体
按理来说*ppList就已经是pNewList了而pNewList又是指向一个堆区的结构体
我就想在编译器中会不会将*ppList直接解析为一个指针?但是看到createlist1中有*ppList这样的语句然后我想了二十分钟把所有可能性想完了就一个没想了,符号的优先级!!!!!!!!!!!!!
然后(*ppList)->pTailOfData ->next = pNew;


我选择强颜欢笑。
链表代码
/*
适用于标准C
LinkList.c
无序单链表的实现代码
*/
#include <stdio.h>
#include <stdlib.h>
#include <string.h> //for memcpy
#define OK 1
#define OVERFLOW 0
#define LIST_INIT_SIZE 100
#define LISTINCREMENT 10
//公共错误码,项目组成员之间的共同约定
#define MALLOC_ERROR -1
#define NOTFIND -2
#define PARAM_ERROR -3
#define REALLOC_ERROR -4
#define END_ID 0
typedef struct person
{
long ID; //4
char name[20]; //20
}Elemtype;
//单链表的单个数据结点的类型定义
typedef struct NODE
{
Elemtype data; //28
struct NODE *next; //4
}NODE, *pNODE; //如果定义数据结点的对象或变量,每个变量有24+4=28个字节
//单链表整体结构的类型定义
typedef struct LIST
{
int Count; //数据个数,即表长。该信息使用频繁,3种思路可做:
//1. 定义为pubblic权限的成员变量Count,增删清空等时候维护该变量,获取时直接以list1.Count的形式返回——有安全风险,且容易引发混乱,不提倡
//2. 定义成成员方法getCount()的形式,调用方法,临时去计算并返回长度值。 ——计算费时,不适合频繁使用,尤其是数据量很大的时候
// 3. 定义为private权限的成员变量Count,增删清空等时候维护该变量,获取时用public权限的成员方法getCount()去读取该变量。——这是实际普遍使用的方式
struct NODE *pHeadOfData; //指向单链表表头的指针,即书上所说的head指针。必须是private权限的,不允许其他类的对象来修改这个成员的值,对使用链表的程序员透明(即:不需要知道它的存在)。指向表头结点,一旦创建了链表对象,在销毁之前永不变。
//下面是不太重要或常用的一些成员,同学们可以自由发挥想一下,例如如下:
int maxValue; //一个并不成熟的设计,要求数据必须是可相互比较的类型,且删除后不好维护
int minValue;
struct NODE *pTailOfData; //以方便快速定位到表尾结点(在数据的尾插法中可以用到)
// ......
}LIST, *LINKLIST; //如果定义对象,则每个对象有4+4+4+4=16个字节
/*****************************************************************
* 函数名字:SearchByPos
* 函数功能:查询指定的单链表中指定位置的元素,获得其数据结点的地址
* 函数参数:pList ——指向某单链表对象的一级指针,要求非空
* pos ——所搜数据在表中的逻辑位置(编号从0开始)
* ppNode——向主调函数传出(加一级指针)该表的第pos个结点的地址(一级指针),故此处需要用1+1=2级指针的参数类型
* 如果没找到第pos个元素,则该参数返回NULL,即0x00000000
* 函数返回:int型,0表示操作正常结束; -2(NOTFIND)表示没找到; -3(PARAM_ERROR)表示参数校验失败
* 备 注:同学们可以自己写SearchByValue函数
* 该函数如果在类中,可设为public权限,开放
*/
//根据逻辑顺序值pos,在单链表pList中,将第pos个元素结点的地址值以参数形式传出。
int SearchByPos(LIST *pList, int pos, NODE **ppNode)
{
int i;
NODE *p;
//参数校验
if (pList==NULL)
{
return PARAM_ERROR;
}
i= 0;
p= pList->pHeadOfData;
while ( i<pos && p->next!= NULL) //当没有数到逻辑顺序的第i个结点 并且 还没有到表尾的时候,则
{
p= p->next; //一边将p指针指向下一个结点
i++; //一边计数
}
if ( i==pos ) // 如果 i== pos,即p指向第pos个元素了
{
*ppNode= p; //如果是以“找到第pos个元素”的姿态跳出while循环
return 0;
}
else //如果是p->next== NULL,即以“到表尾”的姿态跳出while循环
{
*ppNode= NULL;
return NOTFIND;
}
}
/*****************************************************************
* 函数名字:Insert
* 函数功能:插入一个元素到指定的单链表中的指定位置后
* 函数参数:pList——指向某单链表对象的一级指针,要求非空
* value——需要添加或插入的元素的值,假定元素值是有效的; 可稍作改动,支持结构体变量类型
* pos ——需要插入的逻辑位置(之后),pos大于表长时视为“表尾追加元素”,pos<=0时视为“表头后插入元素”
* 函数返回:int型,0表示操作正常结束
* 备 注:本函数不对上层程序员开放。在无序表中,不需要指定插入的位置(因为无序表中元素的先后顺序并不重要。在Java或C++的有些类中,也提供了这种插入操作,主要是在指定位置之前插入。同学们可以自行设计和尝试改写下面代码)
* 在有序表中,其该插入的位置是由其值的大小来决定的,无须指定插入位置pos;而且,有序表,主要都用在顺序表中,很少有用在单链表里的情况。查找很不方便哦!折半查找没法用!(作为练手,同学们可以尝试编写这个插入方法)
* 该函数如果在类中,可设为private权限,不开放
*/
int Insert(LIST *pList, Elemtype value, int pos)
{
long len;
int ret;
struct NODE *pNew= NULL;
struct NODE *pPre= NULL;
//参数校验
if (pList==NULL)
{
return PARAM_ERROR;
}
//参数调整
len= pList->Count; //将长度信息读出来备用,len变量不定义也是可以的。
if (pos >= len)
pos= len;
if (pos <0)
pos= 0;
//插入第一步:申请新结点空间
pNew= (struct NODE *)malloc(sizeof(struct NODE));
if (pNew==NULL)
{
return MALLOC_ERROR;
}
//插入第二步:填值到新结点空间,准备就绪
memset(pNew, 0, sizeof(struct NODE));
pNew->data.ID= value.ID; //此处不能直接写成pNew->data= value;
memcpy(pNew->data.name, value.name, strlen(value.name));
pNew->next= NULL;
//插入第三步:找到第pos个结点,以备在其后插入新结点
ret= SearchByPos(pList, pos, &pPre);
if (ret== NOTFIND)
{
free(pNew);
return NOTFIND;
}
//插入第四步:插入结点
pNew->next= pPre->next;
pPre->next= pNew;
//插入第五步:长度值别忘了+1
pList->Count++;
return 0;
}
/*****************************************************************
* 函数名字:AddToTail
* 函数功能:往“无序”的线性“表尾”后面添加一个元素(即:在表尾追加一个元素结点)
* 函数参数:pList——指向某单链表对象的一级指针,要求非空
* value——需要添加的元素的值,假定元素值是有效的; 可稍作改动,支持结构体变量类型
* 函数返回:int型,0表示操作正常结束
* 备 注:该函数如果在类中,可设为public权限,开放给上层程序员使用
*/
int AddToTail(LIST *pList, Elemtype value) //AddToTail(pList1, value);
{
int len;
len= pList->Count;
return Insert(pList, value, len);
}
/*****************************************************************
* 函数名字:AddToHead
* 函数功能:往“无序”的线性“表头”后面添加一个元素结点
* 函数参数:pList——指向某单链表对象的一级指针,要求非空
* value——需要添加的元素的值,假定元素值是有效的; 可稍作改动,支持结构体变量类型
* 函数返回:int型,0表示操作正常结束
* 备 注:该函数如果在类中,可设为public权限,开放给上层程序员使用
*/
int AddToHead(LIST *pList, Elemtype value)
{
return Insert(pList, value, 0); //在第一个元素之前(即:第0个元素之后)插入元素结点
}
/*****************************************************************
* 函数名字:createList
* 函数功能:创建一个空的带表头节点的单向链表
* 函数参数:ppList——是一个2级指针,调用结束后*ppList指向一个单链表结构的对象
* 函数返回:int型,0表示操作正常结束
* 备 注:该函数如果在类中,可设为public权限,开放给上层程序员使用
*/
//创建一个带表头结点的链表,完成数据输入和串接
int createList(LIST **ppList) //一般我们都将指向单链表第一个结点(或表头结点)的指针命名为head,这是习惯约定
{
struct LIST *pNewList;
struct NODE *pNewNode;
if (ppList==NULL) //参数校验,注意:此处校验的是ppList(不能为空,口袋必须要有!),不是*ppList(可以为NULL,表示有口袋,但是口袋里什么东西都没有)。
return PARAM_ERROR;
//创建一个表头结点,并用pNewList指向该空间
pNewNode = (struct NODE *)malloc(sizeof(struct NODE)); //申请空间,注意:申请的是一个表结点的空间(28个字节)
if (pNewNode==NULL)
{
return MALLOC_ERROR;
}
memset(pNewNode, 0, sizeof(struct NODE));//void *memset(void *s,int c,size_t n)
//总的作用:将已开辟内存空间 s 的首 n 个字节的值设为值 c。
//从pNewNode
pNewNode->next = NULL; //空表,没有后续结点。表头结点的data域不需要处理,清0即可。另,养成良好习惯,当结点的next成员指向何方尚不明朗时,先置为NULL以防患于未然,避免野指针。
//创建一个表对象的空间,并用pNewList指向该空间
pNewList = (struct LIST *)malloc(sizeof(struct LIST)); //申请空间,注意:申请的是一个表对象的空间(16个字节),而不是一个表结点的空间(28个字节)
if (pNewList==NULL)
{
free(pNewNode); //在发生异常,准备退出之前,先把之前成功申请的pNewNode结点空间给释放了!这一点很多程序员容易忽略,造成内存泄露!
// 两个没有关联 为什么要释放???//堆区的东西,释放,不然没人回收
return MALLOC_ERROR;
}
memset(pNewList, 0, sizeof(struct LIST));
pNewList->Count= 0; //设置该空表头的表长值为0
pNewList->pHeadOfData = pNewNode; //表对象的数据指针指向刚才建好的表头结点。
pNewList->pTailOfData= pNewNode;
*ppList = pNewList; //给表头指针赋值为表头结点的地址。
//这是套路,先用一个临时变量pNewList去操作数据,然后交付给*ppList
return 0; //本函数是如何返回表头指针的?又如何调用本函数呢?思考这2个问题!能画出内存四区图来么?
}
/*****************************************************************
* 函数名字:createList2
* 函数功能:创建一个单向链表,并填入数据,以尾插法实现结点挂接。
* 函数参数:
* 函数返回:LIST ** (函数运行结束之后,返回指向该表对象空间的一个2级指针)
* 备 注:以前数据结构的老版本,没学过面向对象思想的人才会这么写
这个方法不是面向对象的思想!不会成为单链表类的一个成员函数。写在这里,只是为了给同学们展示目前大多数教科书或考题中的一个不成熟的考法。
*/
//创建一个带表头结点的链表,并且完成数据输入和串接
int createList2(LIST **ppList)
{
struct NODE *pNew;
struct NODE *pTail;
Elemtype Data;
if (ppList==NULL) //参数校验
return PARAM_ERROR;
createList(ppList); //调用之前定义的函数,产生一个空表
printf("请输入学生的5位证件号的值和姓名(空格隔开,ID值为0表示输入结束):");
scanf("%ld", &(Data.ID));
scanf("%s", Data.name);
//创建并挂接后续的各个结点
while (Data.ID != END_ID) //程序员和用户已约定:当用户输入的数据为0(END_ID)时,表示数据录入的结束(注意,此约定不是唯一方法,仅供学习时适用)
{
//创建新的结点并赋值
pNew = (struct NODE *)malloc(sizeof(struct NODE)); //申请空间
if (pNew==NULL)
{
return MALLOC_ERROR;
}
memset(pNew, 0, sizeof(struct NODE));
pNew->data.ID= Data.ID; //为新结点的data域填入数据
memcpy(pNew->data.name, Data.name, strlen(Data.name));
pNew->next = NULL; //为新结点的next域填入数据,指向不行时填入NULL;或因为其是新的表尾结点,所以也应该将其next域填入NULL表示链表在结尾。
//将新结点挂接到原链表中,此步骤很关键!
/* pTail->next = pNew; //pTail专门指向链表当前的最后一个结点,此行代码实现了将新结点连入链表尾部
pTail = pNew; //pTail指向的结点已经不是链表的表尾结点了(挂接之后,pNew指向的结点才是新的表尾结点),故而刷新pTail,让其指向新的表尾结点。
*/
(*ppList)->pTailOfData->next = pNew;
(*ppList)->pTailOfData= pNew;
printf("请输入学生的5位证件号的值和姓名(空格隔开,ID值为0表示输入结束):");
scanf("%ld", &(Data.ID));
scanf("%s", Data.name);
}
return 0; //本函数是如何返回一个表的?思考这个问题!
}
/*****************************************************************
* 函数名字:output
* 函数功能:输出单链表的所有结点数据,在屏幕上显示打印
* 函数参数:pList——指向某单链表对象的一级指针,要求非空(有了它,我们就能顺藤摸瓜,找出所有数据)
* 函数返回:无(这是一个打印或显示类型的函数,不需要返回任何数据)
*/
void output(struct LIST *pList)
{
struct NODE *p;
if (pList==NULL) //参数如果不正确,则直接罢工
return;
p = pList->pHeadOfData->next; //"顺藤",从pHeadOfData->next开始,跳过表头节点的Data域不打印
while (p != NULL) //到尾。注意,单链表的最后一个结点的next域的值为NULL,本块代码也是读取单链表的标准模板
{
printf("%6d ", p->data.ID); //"摸瓜"
printf("%s\n", p->data.name);
p = p->next; //千万别忘记本行代码,否则死循环了
}
return ;
}
/*****************************************************************
* 函数名字:DelByPos
* 函数功能:删除指定单链表中指定逻辑顺序位置的元素结点,并将删除的元素的值提取出来
* 函数参数:pList ——指向某单链表对象的一级指针,要求非空
* pos ——需要删除的结点的逻辑序号(从0开始编号),pos大于表长或者pos<=0时视为“参数不合法”
* pValue——指向被删除元素的值,以方便在有些应用场合中对其做死前最后可能的访问操作。
* 函数返回:int型,0表示操作正常结束
* 备 注:该函数如果在类中,可设为public权限,开放。
*/
int DelByPos(struct LIST *pList, int pos, Elemtype *pValue)
{
int ret;
struct NODE *pDel= NULL;
struct NODE *pPre= NULL;
//参数校验
if (pList==NULL)
{
return PARAM_ERROR;
}
//删除第一步:找到第pos-1个结点的地址,顺带着也就校验了pos值是否过大
ret= SearchByPos(pList, pos-1, &pPre); //要删除第pos个元素,在链表这种结构中,需要获取到第pos-1个元素的地址,以方便删除操作
if (ret== NOTFIND) //如果本来该表压根就没有第pos-1个元素,那无法完成删除,pos值过大!
{
return PARAM_ERROR;
}
//删除第二步:获取第pos个结点的地址并暂存该地址(函数的任务就是要删这个结点)
pDel= pPre->next;
if (pDel==NULL) //有第pos-1个结点,但恰好没有第pos个结点的情况,仍然归咎于pos参数传入错误
{
return PARAM_ERROR;
}
//删除第三步:将第pos个结点从链表中摘下来,使其脱离链表
pPre->next= pPre->next->next;
//删除第四步:(非必须的步骤)将该结点的值拷贝出来,以备上层函数可能使用
pValue->ID= pDel->data.ID;
memcpy(pValue->name, pDel->data.name, strlen(pDel->data.name));
//删除第五步:释放pDel指针所指向的结点空间(在堆区),注意,并不是释放pDel指针变量本身这4个字节哦!free之后,pDel变量仍然存在!成为了一个野指针!
free(pDel);
pDel=NULL; //指针复位操作。可以看出,pDel指针仍然存在,有值,但其指向的空间已被回收。为了避免误操作,特意将这4个字节的空间全部清0,即让pDel指针为NULL
//删除第六步:长度值别忘了-1
pList->Count--;
return 0;
}
// 思考下面的这些操作应该怎么去设计参数和操作思想?
/*****************************************************************
* 函数名字:clearList
* 函数功能:清空一个单向链表的数据
* 函数参数:pList——是一个指向表对象空间的1级指针。
* 函数返回:int型,0表示操作正常结束
* 备 注:只是清空操作,表对象仍然存在,只是没数据而已。所以表对象指针不会发生变化,没必要用二级指针,一级指针就能搞定。
*/
int clearList(LIST *pList)
{
// 参数校验
// ......
// 做好循环控制并针对每个数据结点,释放结点空间。建议用while循环,想想循环结束条件是什么?
// ......
// pHeadOfData指针复位
// ......
// 调整表长,恢复为0 ,此步骤千万别忘了!
// ......
return 0;
}
/*****************************************************************
* 函数名字:destroyList
* 函数功能:销毁一个单向链表
* 函数参数:ppList——是一个2级指针,因为要销毁空间,所以需要在函数内改变实参的值(往外传一个NULL),所以要用2级指针
* 函数返回:int型,0表示操作正常结束
* 备 注:
*/
int destroyList(LIST **ppList)
{
// 参数校验
// ......
// 清空数据并销毁数据
// ......
// 释放表对象所占空间
// ......
// 表对象指针复位
// ......
return 0;
}
/*****************************************************************
* 函数名字:MergeList
* 函数功能:将2个单链表进行无序合并,合并后不改变原有的2个表的数据。
* 函数参数:pList1——指向某单链表对象1的一级指针,要求非空
* pList2——指向某单链表对象2的一级指针,要求非空
* 函数返回:int型,0表示操作正常结束
* 备 注:
*/
// int MergeList(LIST *pList1, LIST *pList2)
// int MergeList(LIST **ppList1, LIST *pList2)
// LIST * MergeList(LIST *pList1, LIST *pList2)
// ......
int main(void)
{
int ret, pos;
struct LIST *pList1;
// struct LIST *pList2;
Elemtype value;
//创建链表1,并填入数据
ret= createList(&pList1); // 一定要看清楚此处的用法哦!pList1是一级指针,所以&pList1就是二级指针了(一级指针的地址,有些书上称之为二级指针类型了)!
value.ID= 10;
memset(value.name, 0, 20);
memcpy(value.name,"汤唯", 4);
AddToTail(pList1, value);
value.ID= 20;
memset(value.name, 0, 20);
memcpy(value.name,"林志玲", 6);
AddToTail(pList1, value);
value.ID= 30;
memset(value.name, 0, 20);
memcpy(value.name,"关之琳", 6);
AddToTail(pList1, value);
value.ID= 40;
memset(value.name, 0, 20);
memcpy(value.name,"迪丽热巴", 8);
AddToTail(pList1, value);
output(pList1); //输出显示单链表的所有数据
printf("=========下面演示删除=====================\n");
pos= 8;
ret= DelByPos(pList1, pos, &value); //删除第8个。但是不存在第8个结点,删除失败,返回-1,放弃删除(你也可以编程实现让它在这种情况下(pos>count时)去删除最后一个结点来作为对用户的回应)
if (ret== 0)
printf("我删除了%s这个结点\n", value.name);
else
printf("我没法删除第%d个结点\n", pos);
output(pList1); //输出显示单链表的所有数据
// printf("=========下面用过时的创建函数演示一下========\n");
// ret= createList2(&pList2); //用老方法来创建,在创建的同时就在插入元素,模块的划分有点混乱
// output(pHead2);
return 0;
}